Pix2Pixの仕組みと実装方法を解説!画像変換の基礎から応用まで
Pix2Pixは、画像変換タスクにおいて革新的な手法として注目を集めています。この記事では、Pix2Pixの仕組みとその実装方法について、基礎から応用まで詳しく解説します。Conditional GANを基にしたこの手法は、入力画像から対応する出力画像を生成する能力を持ち、様々な分野で活用されています。具体的には、エンコーダー、ジェネレーター、ディスクリミネーターの3つの主要な要素がどのように連携して画像変換を実現するのかを説明します。さらに、復元損失関数と敵対的損失関数を組み合わせた学習プロセスについても触れます。実装にはTensorFlowやPyTorchなどのディープラーニングフレームワークが使用され、絵画様式の変換や医療画像解析など、多岐にわたる応用例を紹介します。この記事を通じて、Pix2Pixの基礎から応用までの全体像を理解し、実際に実装するための知識を身につけることができます。
イントロダクション
Pix2Pixは、2017年にIsolaらによって提案された画像翻訳タスクのための手法で、Conditional GAN(Generative Adversarial Networks)を基にしています。この手法は、入力画像に対応する出力画像を生成することで、画像変換を実現します。Pix2Pixのアーキテクチャは、エンコーダー、ジェネレーター、ディスクリミネーターの3つの要素で構成され、復元損失関数と敵対的損失関数を組み合わせて学習を行います。実装にはTensorFlowやPyTorchなどのディープラーニングフレームワークが使用され、絵画様式の変換や医療画像解析など、様々な分野で応用されています。学習には大量のペアデータが必要で、深層学習の基礎知識とプログラミングスキルが求められます。
Pix2Pixとは?
Pix2Pixは、2017年にIsolaらによって提案された画像翻訳タスクのための手法です。この手法は、Conditional GAN(Generative Adversarial Networks)を基にしており、入力画像に対応する出力画像を生成することで、画像変換を実現します。Pix2Pixのアーキテクチャは、エンコーダー、ジェネレーター、ディスクリミネーターの3つの要素で構成されています。これらの要素は、復元損失関数と敵対的損失関数を組み合わせて学習を行います。
Pix2Pixの実装には、TensorFlowやPyTorchなどのディープラーニングフレームワークが使用されます。この手法は、絵画様式の変換や医療画像解析など、様々な分野で応用されています。ただし、学習には大量のペアデータが必要であり、深層学習の基礎知識とプログラミングスキルが求められます。Pix2Pixは、画像変換の基礎から応用まで幅広く活用される重要な技術です。
Conditional GANの基本概念
Conditional GAN(Generative Adversarial Networks)は、GANの一種であり、特定の条件に基づいてデータを生成するモデルです。通常のGANでは、ランダムなノイズからデータを生成しますが、Conditional GANでは、入力データ(条件)を指定することで、その条件に応じたデータを生成します。この特性を活かし、Pix2Pixでは入力画像に対応する出力画像を生成するタスクに適用されています。
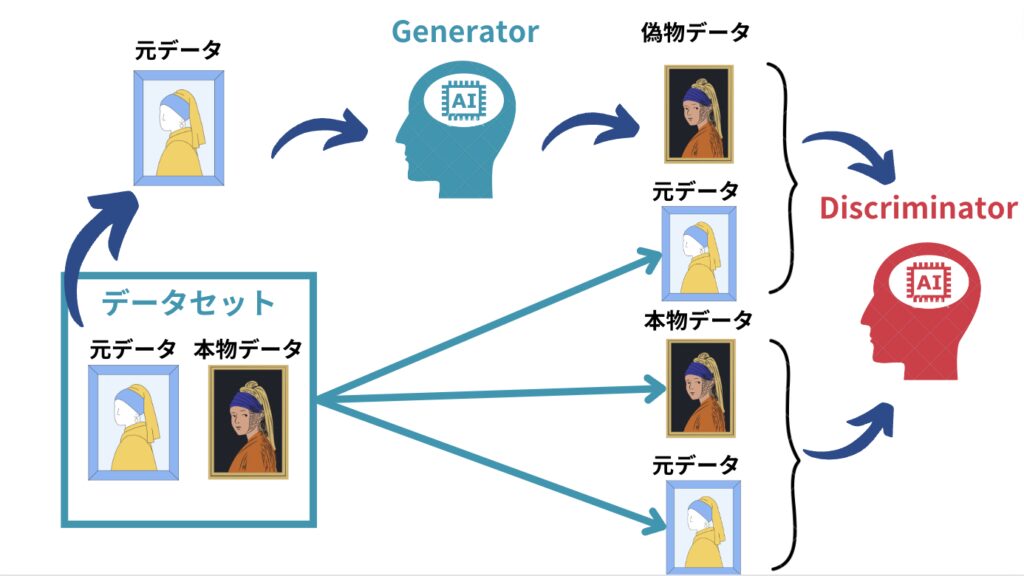
Conditional GANの基本的な構造は、ジェネレーター(Generator)とディスクリミネーター(Discriminator)の2つのネットワークで構成されています。ジェネレーターは、入力画像から出力画像を生成する役割を担い、ディスクリミネーターは、生成された画像が本物か偽物かを判別します。この2つのネットワークが互いに競い合うことで、生成される画像の品質が向上していきます。
Pix2Pixでは、さらにエンコーダー(Encoder)が加わり、入力画像の特徴を抽出します。エンコーダーは、画像の重要な情報を圧縮し、ジェネレーターに渡すことで、より正確な画像変換を実現します。このように、Conditional GANの基本概念を理解することで、Pix2Pixの仕組みをより深く理解することができます。
Pix2Pixのアーキテクチャ
Pix2Pixのアーキテクチャは、Conditional GAN(条件付き敵対的生成ネットワーク)を基盤として構築されています。このモデルは、入力画像と出力画像のペアを学習し、特定の条件下でリアルな画像を生成することを目的としています。アーキテクチャは主に3つの要素で構成されます。まず、エンコーダーが入力画像を特徴量に変換し、次にジェネレーターがその特徴量を基に新しい画像を生成します。最後に、ディスクリミネーターが生成された画像と本物の画像を区別する役割を担います。
ジェネレーターは、U-Netと呼ばれる構造を採用しており、エンコーダーとデコーダーの間にスキップ接続を設けることで、詳細な情報を保持しながら画像を生成します。これにより、高品質な出力画像が得られます。一方、ディスクリミネーターはPatchGANと呼ばれる手法を用いて、画像全体ではなく局所的な領域ごとにリアルかどうかを判定します。これにより、細部までリアルな画像を生成することが可能になります。
学習プロセスでは、復元損失関数と敵対的損失関数の2つを組み合わせて使用します。復元損失関数は、生成された画像と正解画像の差異を最小化する役割を担い、敵対的損失関数はディスクリミネーターを欺くことで、よりリアルな画像を生成することを目指します。これらの損失関数を最適化することで、Pix2Pixは高精度な画像変換を実現します。
エンコーダーとジェネレーターの役割
Pix2Pixのアーキテクチャにおいて、エンコーダーとジェネレーターは重要な役割を果たします。エンコーダーは、入力画像を低次元の特徴量に変換する役割を担います。これにより、画像の重要な情報を抽出し、ジェネレーターが理解しやすい形に圧縮します。このプロセスは、画像の特徴を捉えるための重要なステップであり、畳み込みニューラルネットワーク(CNN)を基盤としています。
ジェネレーターは、エンコーダーが抽出した特徴量を基に、新しい画像を生成します。この際、U-Netと呼ばれるアーキテクチャがよく使用されます。U-Netは、エンコーダーで圧縮された特徴量をデコードし、元の画像サイズに戻す役割を果たします。このプロセスでは、スキップ接続が使用され、エンコーダーの各層の情報を直接ジェネレーターに伝えることで、詳細な情報の損失を防ぎます。これにより、高品質な出力画像が生成されます。
エンコーダーとジェネレーターの連携は、Pix2Pixの画像変換タスクにおいて不可欠です。エンコーダーが入力画像の特徴を捉え、ジェネレーターがその特徴を基に新しい画像を生成することで、入力と出力の間に意味のある対応関係が構築されます。この仕組みにより、Pix2Pixは画像翻訳やスタイル変換など、多様な応用が可能となっています。
ディスクリミネーターの仕組み
ディスクリミネーターは、Pix2Pixの重要なコンポーネントの一つであり、生成された画像が本物か偽物かを判別する役割を担っています。この仕組みは、敵対的学習の核心部分であり、ジェネレーターがよりリアルな画像を生成するためのフィードバックを提供します。ディスクリミネーターは、入力として本物の画像とジェネレーターが生成した画像の両方を受け取り、それぞれが本物である確率を出力します。この出力を基に、ジェネレーターは自身の生成能力を向上させます。
ディスクリミネーターのアーキテクチャは、一般的に畳み込みニューラルネットワーク(CNN)を基に構築されます。これにより、画像の局所的な特徴を効果的に捉えることが可能です。学習プロセスでは、ディスクリミネーターは本物の画像を正しく識別し、偽物の画像を検出する能力を高めるために訓練されます。一方で、ジェネレーターはディスクリミネーターを欺くようなリアルな画像を生成することを目指します。この相互作用が、Pix2Pixの学習を進化させる原動力となります。
敵対的損失関数は、ディスクリミネーターとジェネレーターの間の競争を定量化するために使用されます。この損失関数は、ディスクリミネーターが本物と偽物を正確に識別する能力を最大化し、ジェネレーターがディスクリミネーターを欺く能力を最大化するように設計されています。このバランスが、Pix2Pixの画像変換タスクにおいて高品質な結果を生み出す鍵となります。
損失関数の詳細
損失関数は、Pix2Pixの学習プロセスにおいて重要な役割を果たします。Pix2Pixでは、主に復元損失(L1損失)と敵対的損失(GAN損失)の2つの損失関数が組み合わされています。復元損失は、生成された画像と正解画像の間のピクセルレベルの差を最小化することを目的としています。これにより、生成される画像が入力画像の詳細を正確に反映するようになります。一方、敵対的損失は、ジェネレーターとディスクリミネーターの間の競争を促進します。ジェネレーターは、ディスクリミネーターを欺くようなリアルな画像を生成しようとし、ディスクリミネーターは生成された画像と本物の画像を区別しようとします。この競争を通じて、生成される画像の品質が向上します。
復元損失と敵対的損失の組み合わせにより、Pix2Pixは高品質な画像変換を実現します。復元損失が細部の正確さを保証し、敵対的損失が全体的なリアリティを向上させます。このバランスが、Pix2Pixの成功の鍵となっています。また、これらの損失関数は、勾配降下法を用いて最適化され、モデルのパラメータが更新されます。これにより、ジェネレーターとディスクリミネーターが互いに競い合いながら、より良い性能を発揮するようになります。
Pix2Pixの損失関数は、単に画像の品質を向上させるだけでなく、タスク固有の要件にも対応できる柔軟性を持っています。例えば、医療画像解析では、特定の解剖学的構造を正確に再現することが求められます。このような場合、復元損失を調整することで、特定の領域に重点を置いた学習が可能になります。このように、損失関数の設計は、Pix2Pixの応用範囲を広げる重要な要素となっています。
実装に必要な環境とツール
Pix2Pixを実装するためには、まず適切な環境を整える必要があります。Pythonは必須のプログラミング言語であり、TensorFlowやPyTorchといったディープラーニングフレームワークが広く使用されています。これらのフレームワークは、ニューラルネットワークの構築と学習を効率的に行うための豊富な機能を提供します。また、GPUを活用することで、学習プロセスを大幅に高速化することが可能です。特に、NVIDIAのCUDA対応GPUは、ディープラーニングの計算を高速化するために推奨されます。
さらに、開発環境としてJupyter NotebookやGoogle Colabを利用することで、コードの実行とデバッグをインタラクティブに行うことができます。Google Colabはクラウドベースの環境であり、無料でGPUリソースを利用できるため、初心者にも適しています。データの前処理や可視化には、NumPyやMatplotlib、Pillowといったライブラリが役立ちます。これらのツールを組み合わせることで、Pix2Pixの実装をスムーズに進めることができます。
最後に、GitやGitHubを活用してコードのバージョン管理を行うことも重要です。これにより、プロジェクトの進捗を効率的に管理し、他の開発者とのコラボレーションを容易にすることができます。適切な環境とツールを整えることで、Pix2Pixの実装を成功させるための基盤が整います。
データセットの準備と前処理
データセットの準備は、Pix2Pixの学習において最も重要なステップの一つです。Pix2Pixは、入力画像とそれに対応する出力画像のペアデータを必要とします。例えば、建物のスケッチから実際の写真を生成する場合、スケッチと写真のペアがデータセットとして必要です。これらのデータは、公開されているデータセットを利用するか、独自に収集する必要があります。データセットの品質と量は、モデルの性能に直接影響を与えるため、慎重に準備することが求められます。
前処理の段階では、データセットをモデルが扱いやすい形式に整える必要があります。一般的には、画像のサイズを統一し、正規化を行います。例えば、画像のピクセル値を0から1の範囲にスケーリングすることで、学習の安定性を向上させることができます。また、データ拡張(Data Augmentation)を適用することで、モデルの汎化性能を高めることも可能です。データ拡張には、回転、反転、クロップなどの手法が用いられます。これらの前処理を適切に行うことで、モデルの学習効率と精度を向上させることができます。
学習プロセスの流れ
Pix2Pixの学習プロセスは、ジェネレーターとディスクリミネーターの2つのネットワークが互いに競合しながら進められます。ジェネレーターは、入力画像から目的の出力画像を生成する役割を担います。一方、ディスクリミネーターは、生成された画像が本物か偽物かを判別する役割を果たします。この競合を通じて、ジェネレーターはよりリアルな画像を生成する能力を向上させます。
学習の初期段階では、ジェネレーターが生成する画像は粗く、ディスクリミネーターは簡単に偽物と判別できます。しかし、学習が進むにつれて、ジェネレーターはディスクリミネーターを欺くために、より詳細でリアルな画像を生成するようになります。このプロセスは、敵対的損失関数によって制御され、ジェネレーターとディスクリミネーターのバランスを保ちながら進められます。
さらに、Pix2Pixでは復元損失関数も使用されます。これは、生成された画像が入力画像とどれだけ一致しているかを評価するもので、画像の構造や内容を正確に保つために重要です。復元損失関数と敵対的損失関数を組み合わせることで、Pix2Pixは高品質な画像変換を実現します。この学習プロセスは、大量のペアデータを用いて繰り返し行われ、最終的には入力画像から目的の出力画像を正確に生成できるモデルが完成します。
応用例と実践的な活用方法
Pix2Pixは、その汎用性の高さから、さまざまな分野で応用されています。例えば、絵画のスタイル変換においては、線画に色を付けるタスクや、写真を特定の芸術スタイルに変換するタスクで活用されています。これにより、アーティストやデザイナーがアイデアを迅速に視覚化するためのツールとして利用されています。また、医療画像解析の分野では、MRIやCTスキャン画像から特定の病変部分を強調する画像を生成するなど、診断支援に役立つ技術として注目されています。
さらに、建築設計や都市計画の分野でも、Pix2Pixは有用です。例えば、設計図からリアルな3Dモデルを生成したり、都市の衛星画像から土地利用の分類を行うことが可能です。これにより、設計プロセスの効率化や、都市開発の計画立案に貢献しています。また、ファッション業界では、スケッチから実際の衣服のデザインを生成するなど、クリエイティブな作業をサポートするツールとしても活用されています。
実践的な活用においては、データセットの準備が重要です。Pix2Pixは教師あり学習のため、入力画像と出力画像のペアデータが必要です。例えば、線画と着色済み画像のペアや、衛星画像と地図のペアなど、タスクに応じた適切なデータセットを構築することが求められます。また、ハイパーパラメータの調整や学習時間の管理も、実用的なモデルを構築する上で重要なポイントです。これらの要素を適切に調整することで、高品質な画像変換を実現できます。
まとめ
Pix2Pixは、Conditional GANを基にした画像翻訳タスクのための手法であり、入力画像に対応する出力画像を生成することを目的としています。この手法は、エンコーダー、ジェネレーター、ディスクリミネーターの3つの主要な要素で構成されています。エンコーダーは入力画像を特徴量に変換し、ジェネレーターはその特徴量から出力画像を生成します。ディスクリミネーターは、生成された画像が本物か偽物かを判別する役割を担います。
Pix2Pixの学習では、復元損失関数と敵対的損失関数を組み合わせて使用します。復元損失関数は、生成された画像が入力画像とどれだけ一致しているかを評価し、敵対的損失関数は、生成された画像が本物と見分けがつかないかどうかを評価します。これにより、高品質な画像変換が可能となります。
実装には、TensorFlowやPyTorchなどのディープラーニングフレームワークが使用されます。これらのフレームワークを使用することで、比較的簡単にPix2Pixのモデルを構築し、学習を行うことができます。ただし、学習には大量のペアデータが必要であり、深層学習の基礎知識とプログラミングスキルが求められます。
Pix2Pixは、絵画様式の変換や医療画像解析など、様々な分野で応用されています。例えば、線画から写真のような画像を生成したり、医療画像から病変部分を強調した画像を生成したりすることが可能です。これらの応用例は、Pix2Pixの汎用性と有用性を示しています。
まとめとして、Pix2Pixは、画像変換タスクにおいて非常に強力な手法であり、その仕組みと実装方法を理解することで、様々な応用が可能となります。深層学習の基礎知識とプログラミングスキルを身につけることで、Pix2Pixを活用した画像変換プロジェクトに取り組むことができるでしょう。
よくある質問
Pix2Pixとはどのような技術ですか?
Pix2Pixは、画像変換を行うための深層学習モデルの一種です。この技術は、Conditional Generative Adversarial Networks(cGANs)を基盤としており、入力画像から特定の出力画像を生成することを目的としています。例えば、白黒画像をカラー画像に変換したり、線画をリアルな画像に変換したりする際に使用されます。Pix2Pixの特徴は、ペアデータ(入力画像と対応する出力画像のセット)を必要とすることです。これにより、モデルは入力と出力の関係性を学習し、高精度な画像変換を実現します。
Pix2Pixの学習プロセスはどのように進みますか?
Pix2Pixの学習プロセスは、ジェネレータとディスクリミネータという2つのニューラルネットワークが競合することで進みます。ジェネレータは、入力画像から出力画像を生成する役割を担います。一方、ディスクリミネータは、生成された画像が本物か偽物かを判別する役割を果たします。この競合を通じて、ジェネレータは次第にリアルな画像を生成できるようになり、ディスクリミネータはより正確に偽物を見分ける能力を高めます。このプロセスは、敵対的学習と呼ばれ、モデルの性能向上に寄与します。
Pix2Pixの実装にはどのような環境が必要ですか?
Pix2Pixの実装には、Pythonと深層学習フレームワーク(例えば、TensorFlowやPyTorch)が必要です。また、GPUを搭載した計算環境が推奨されます。これは、画像処理やモデルの学習に大量の計算リソースを必要とするためです。さらに、データセットの準備も重要です。Pix2Pixでは、入力画像と出力画像のペアデータが必要となるため、適切なデータセットを用意する必要があります。実装の際には、これらの環境を整えることが最初のステップとなります。
Pix2Pixの応用例にはどのようなものがありますか?
Pix2Pixは、画像変換の幅広い応用が可能です。例えば、建築設計の分野では、スケッチからリアルな建築物の画像を生成するために使用されます。また、医療画像処理では、MRI画像から病変部分を強調した画像を生成するなど、診断支援に役立てられています。さらに、アートやデザインの分野でも、線画からリアルな絵画を生成するなど、クリエイティブな用途にも活用されています。このように、Pix2Pixは多岐にわたる分野で画像生成の可能性を広げています。
コメントを残す
コメントを投稿するにはログインしてください。
関連ブログ記事