AI性能向上の鍵!乱数制御と固定化方法を徹底解説【機械学習・深層学習】
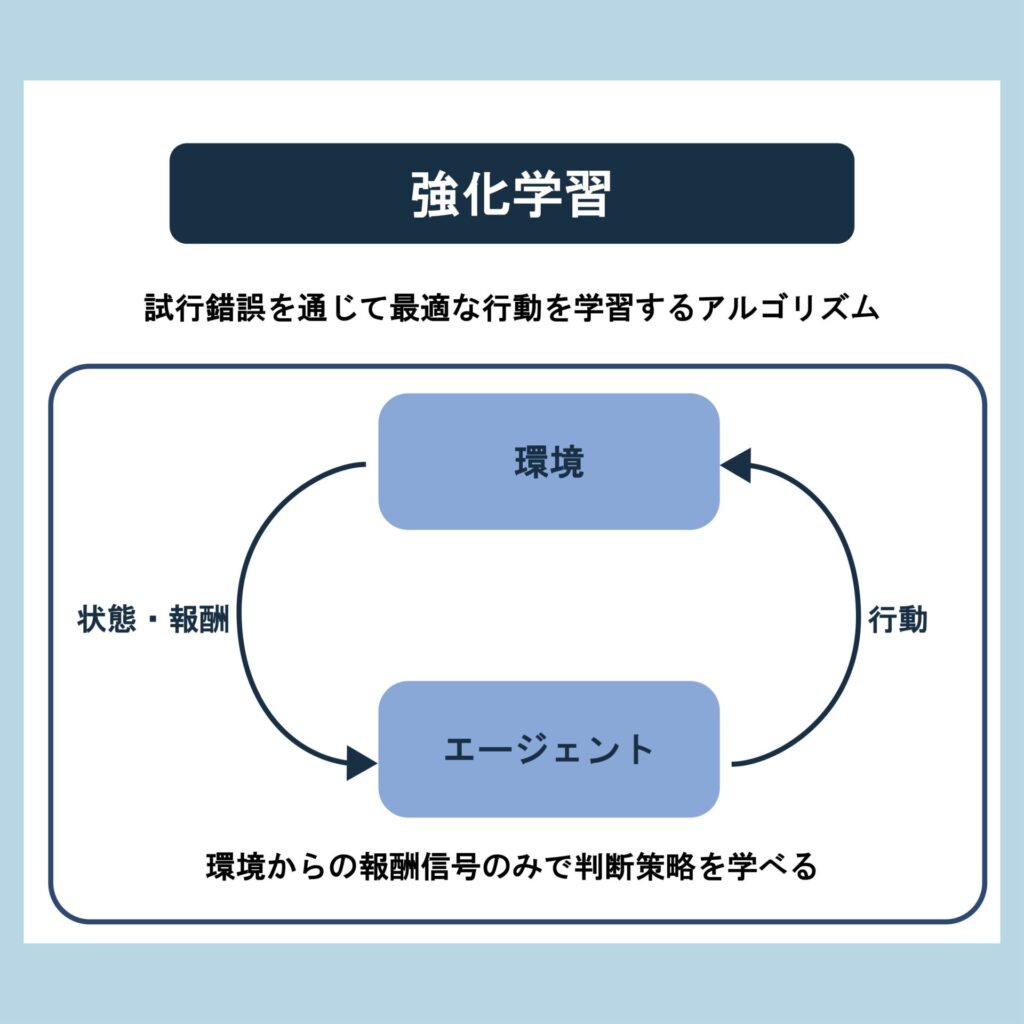
AIの性能向上において、乱数制御は重要な役割を果たします。乱数は、機械学習や深層学習のモデルが学習する際に、初期値の設定やデータのシャッフルなどで使用されます。この乱数を適切に制御することで、モデルの再現性を確保し、学習の安定性を高めることが可能です。本記事では、乱数制御の基本的な概念から、具体的な固定化方法までを解説します。
乱数制御の重要性は、特に再現性を求める場面で顕著です。例えば、同じデータとアルゴリズムを使用しても、乱数の初期値が異なると結果が変わることがあります。これを防ぐために、乱数を固定化する手法が用いられます。固定化には、シード値の設定や、特定の乱数生成アルゴリズムの使用が一般的です。これにより、実験や開発の際に一貫した結果を得ることができます。
さらに、乱数制御は計算効率の向上にも寄与します。乱数を適切に管理することで、不要な計算を削減し、学習プロセスを高速化することが可能です。また、精度向上やコスト削減にもつながるため、AI開発においては欠かせない技術となっています。本記事では、これらのメリットを具体的な例を交えながら詳しく説明します。
将来的には、乱数制御技術が金融リスクマネジメントやサイバーセキュリティなど、さまざまな分野で活用されることが期待されています。これらの分野では、予測不能な要素を制御することが重要であり、乱数制御がその鍵を握っています。本記事を通じて、乱数制御の基礎から応用までを理解し、AI開発に役立てていただければ幸いです。
イントロダクション
AIの性能向上において、乱数制御は非常に重要な要素となっています。乱数は、一見するとランダムで予測不可能な数値ですが、AIの学習プロセスにおいて重要な役割を果たします。特に、機械学習や深層学習のモデルを訓練する際、乱数を適切に制御することで、モデルの再現性や精度を向上させることが可能です。この記事では、乱数制御の基本的な概念から、具体的な固定化方法までを詳しく解説します。
乱数は、AIの学習において初期化やデータのシャッフル、ドロップアウトなどの場面で使用されます。これらのプロセスで乱数を適切に制御しないと、モデルの学習結果が毎回異なる可能性があり、再現性が損なわれてしまいます。そのため、乱数の固定化は、AI開発者にとって必須の技術と言えます。特に、研究や開発の初期段階では、再現性を確保することが重要です。
乱数を制御する方法には、乱数シードの設定や、擬似乱数生成器の使用などがあります。乱数シードを固定することで、同じ条件下で何度でも同じ結果を得ることが可能です。また、擬似乱数生成器を使用することで、ランダム性を保ちつつも、再現性のある乱数を生成することができます。これらの技術を駆使することで、AIモデルの性能を最大限に引き出すことが可能となります。
将来的には、金融リスクマネジメントやサイバーセキュリティなど、多くの分野で乱数制御技術が活用されることが期待されています。これらの分野では、ランダム性と再現性の両方が求められるため、乱数制御の重要性はさらに高まると考えられます。本記事を通じて、乱数制御の基本から応用までを理解し、AI開発に役立てていただければ幸いです。
乱数制御の重要性
乱数制御は、AIの性能向上において非常に重要な役割を果たします。AIモデルの学習プロセスでは、初期化やデータのシャッフル、ドロップアウトなど、多くの場面で乱数が使用されます。これらの乱数が適切に制御されていないと、学習結果が不安定になり、再現性が失われる可能性があります。特に、機械学習や深層学習においては、乱数の影響がモデルの精度や汎化性能に直接的に影響を与えるため、その重要性はさらに高まります。
乱数を制御することで、AIモデルの学習プロセスを安定化させ、再現性を確保することが可能です。例えば、乱数シードを固定することで、同じ条件下で何度でも同じ結果を得ることができます。これは、モデルの評価や比較を行う際に非常に有用です。また、乱数を制御することで、計算速度の高速化や計算リソースの効率的な利用も実現できます。これにより、AI開発のコスト削減や開発サイクルの短縮が期待されます。
さらに、乱数制御は、AIモデルの過学習を防ぐためにも重要な役割を果たします。過学習は、モデルが訓練データに過度に適合し、未知のデータに対する性能が低下する現象です。乱数を適切に制御することで、モデルの汎化性能を向上させ、過学習を抑制することができます。これにより、AIモデルはより実用的な場面で高い性能を発揮できるようになります。
将来的には、乱数制御技術は、金融リスクマネジメントやサイバーセキュリティなど、多くの分野で活用されることが期待されています。これらの分野では、予測精度やセキュリティの向上が求められており、乱数制御によるAIの性能向上が大きな効果をもたらすでしょう。
乱数とは何か
乱数とは、統計的に予測不可能な数値のことを指します。AIの分野では、乱数が学習データの生成やモデルの初期化、ドロップアウトなどの重要なプロセスで使用されます。乱数は、一見ランダムに見えるが、実際には特定のアルゴリズムによって生成される擬似乱数が一般的です。この擬似乱数は、シード値と呼ばれる初期値を基に生成されるため、同じシード値を用いれば同じ乱数列を再現することが可能です。
AIの性能向上において、乱数を適切に制御することは非常に重要です。例えば、機械学習や深層学習のモデルを訓練する際、乱数が異なると結果が大きく変わることがあります。そのため、再現性を確保するために、乱数を固定化する手法が用いられます。乱数を固定化することで、同じ条件下で実験を繰り返し、結果の信頼性を高めることができます。
乱数の固定化方法には、乱数テーブルや乱数ジェネレータ、統計的手法などが利用されます。これらの手法を用いることで、AIの計算速度の向上や精度の向上、さらにはコスト削減が実現されます。将来的には、金融リスクマネジメントやサイバーセキュリティなど、多くの分野で乱数制御技術が活用されることが期待されています。
乱数制御の方法
乱数制御は、AIの学習プロセスにおいて重要な役割を果たします。特に、機械学習や深層学習において、乱数はモデルの初期化やデータのシャッフルなど、さまざまな場面で使用されます。乱数を適切に制御することで、学習の再現性が確保され、モデルの性能を安定させることが可能です。例えば、乱数シードを固定することで、同じ条件下で実験を繰り返し実行できるため、結果の信頼性が高まります。
また、乱数制御には乱数ジェネレータや乱数テーブルなどの技術が用いられます。これらの技術を活用することで、AIモデルが学習データからより効果的にパターンを抽出し、予測精度を向上させることができます。特に、深層学習においては、乱数の影響が大きいため、その制御が不可欠です。乱数を適切に管理することで、計算速度の向上やリソースの効率的な利用も実現できます。
さらに、統計的手法を用いた乱数制御も有効です。これにより、AIが扱うデータの分布を正確に把握し、モデルの学習プロセスを最適化することが可能になります。乱数制御は、AIの性能向上だけでなく、金融リスクマネジメントやサイバーセキュリティなど、幅広い分野での応用が期待されています。
機械学習における乱数制御
機械学習において、乱数制御はモデルの学習プロセスにおいて重要な役割を果たします。乱数は、データのシャッフルや重みの初期化、ドロップアウトの適用など、さまざまな場面で使用されます。特に、深層学習モデルでは、初期重みの設定に乱数が用いられることが多く、これがモデルの収束速度や最終的な性能に大きな影響を与えます。乱数を適切に制御することで、学習の再現性を確保し、モデルの安定性を高めることが可能です。
乱数制御の方法として、シード値の設定が一般的です。シード値を固定することで、同じ条件下で何度でも同じ結果を得ることができます。これは、実験の再現性を確保するために特に重要です。また、乱数ジェネレータの選択も重要で、異なるジェネレータを使用すると、同じシード値でも異なる結果が得られることがあります。そのため、使用する乱数ジェネレータの特性を理解し、適切に選択することが求められます。
さらに、乱数テーブルや統計的手法を用いることで、乱数の生成プロセスをより細かく制御することができます。これにより、特定の分布に従う乱数を生成したり、特定の条件下での乱数の振る舞いを予測したりすることが可能になります。これらの技術を駆使することで、機械学習モデルの性能を最大限に引き出すことが期待されます。
深層学習における乱数制御
深層学習において、乱数制御はモデルの学習プロセスにおいて重要な役割を果たします。特に、ニューラルネットワークの初期化やドロップアウト、データ拡張などの場面で乱数が使用されます。これらのプロセスにおいて、乱数を適切に制御することで、モデルの学習の再現性を確保し、性能の安定化を図ることが可能です。例えば、重みの初期化に乱数を使用する場合、同じ乱数シードを設定することで、異なる実行間でも同じ結果を得ることができます。これにより、実験の再現性が向上し、モデルの性能評価がより信頼性の高いものとなります。
また、乱数の固定化は、特に研究開発や製品化の段階で重要な技術です。乱数を固定することで、同じ条件下で複数回の実験を行い、モデルの性能を正確に比較することができます。これにより、アルゴリズムの改善やハイパーパラメータのチューニングが効率的に行えるようになります。さらに、乱数ジェネレータの選択や設定も重要で、異なる乱数生成アルゴリズムを使用することで、モデルの学習結果に影響を与えることがあります。そのため、適切な乱数生成方法を選択し、それを固定化することが、深層学習モデルの性能向上に直結します。
将来的には、乱数制御技術がさらに進化し、より複雑なタスクや大規模なデータセットに対応できるようになることが期待されています。これにより、金融市場の予測や医療診断、自律走行車の制御など、さまざまな分野での応用が広がるでしょう。乱数制御と固定化の技術は、AIの性能向上において不可欠な要素であり、その重要性は今後も増していくと考えられます。
遺伝的アルゴリズムと乱数制御
遺伝的アルゴリズムは、生物の進化プロセスを模倣した最適化手法の一つであり、乱数制御がその核心的な要素となっています。このアルゴリズムでは、個体群の初期化や突然変異、交叉などの操作において乱数が頻繁に使用されます。特に、乱数を用いることで、探索空間を広くカバーし、局所解に陥るリスクを軽減することが可能です。これにより、AIモデルの学習プロセスが効率的に進み、より優れた解を見つけることが期待されます。
乱数制御の重要性は、遺伝的アルゴリズムの性能に直接影響を与える点にあります。例えば、乱数のシード値を固定することで、同じ条件下での実験を再現可能にし、結果の信頼性を高めることができます。また、乱数ジェネレータの選択やパラメータ設定を最適化することで、計算速度や精度の向上が図られます。これにより、AIモデルの学習時間を短縮しつつ、高い性能を維持することが可能となります。
将来的には、遺伝的アルゴリズムと乱数制御技術の組み合わせが、複雑な問題解決や最適化タスクにおいてさらに重要な役割を果たすことが予想されます。特に、金融分野でのポートフォリオ最適化や、ロボット工学における経路計画など、多岐にわたる応用が期待されています。乱数を効果的に制御し、固定化することで、AIの性能向上に大きく貢献するでしょう。
乱数の固定化方法
乱数の固定化は、AIの学習プロセスにおいて再現性を確保するために重要なステップです。乱数テーブルを使用することで、特定の乱数列を事前に定義し、それを繰り返し利用することが可能になります。これにより、同じ条件下で実験を繰り返しても、常に同じ結果が得られるようになります。特に、機械学習や深層学習のモデル開発において、この手法は非常に有効です。
また、乱数ジェネレータのシード値を固定することも、乱数の固定化に有効な方法です。シード値を設定することで、乱数ジェネレータが生成する乱数列が常に同じになるため、実験の再現性が高まります。この方法は、特に統計的手法を用いた分析やシミュレーションにおいて、重要な役割を果たします。
さらに、統計的手法を用いて乱数を制御することも可能です。例えば、正規分布や一様分布などの確率分布を利用して、特定の範囲内で乱数を生成することができます。これにより、AIモデルの学習データとして、より適切な乱数列を提供することが可能になります。これらの手法を組み合わせることで、AIの性能向上に大きく寄与することが期待されます。
乱数テーブルの活用
乱数テーブルは、AIの学習プロセスにおいて重要な役割を果たします。乱数テーブルは、あらかじめ生成された乱数の集合体であり、これを用いることで再現性の高い実験やシミュレーションが可能となります。特に、機械学習や深層学習のモデル訓練において、乱数テーブルを活用することで、異なる環境下でも同じ結果を得ることができます。これにより、モデルの性能評価や比較が容易になり、研究開発の効率が大幅に向上します。
さらに、乱数テーブルを使用することで、計算リソースの節約も実現できます。通常、乱数をリアルタイムで生成する場合、計算コストがかかりますが、事前に生成された乱数テーブルを利用することで、このコストを削減できます。特に大規模なデータセットを扱う場合や、複雑なモデルを訓練する際には、この方法が有効です。
また、乱数テーブルは、特定の条件下での再現性を確保するためにも利用されます。例えば、金融リスクマネジメントやサイバーセキュリティのシミュレーションでは、正確な再現性が求められます。乱数テーブルを用いることで、これらの分野での信頼性の高い結果を得ることが可能となります。このように、乱数テーブルは、AIの性能向上において不可欠なツールとなっています。
乱数ジェネレータの利用
乱数ジェネレータは、AIの学習プロセスにおいて重要な役割を果たします。特に、機械学習や深層学習のモデルを訓練する際、初期化やデータのシャッフルなどで乱数が使用されます。乱数ジェネレータを適切に制御することで、再現性のある結果を得ることが可能です。例えば、同じ乱数シードを使用することで、異なる環境やタイミングでも同じ結果を再現できます。これは、モデルの開発やデバッグにおいて非常に有用です。
さらに、乱数ジェネレータの性能は、AIの計算速度や精度に直接影響を与えます。高品質な乱数を生成するジェネレータを使用することで、モデルの収束速度が向上し、より正確な予測が可能になります。一方で、乱数の質が低い場合、モデルの性能が低下したり、過学習が発生するリスクがあります。そのため、乱数ジェネレータの選択と設定は、AI開発において慎重に行う必要があります。
また、乱数ジェネレータの応用範囲は広く、金融分野でのリスクシミュレーションや、ゲーム開発におけるランダムイベントの生成など、多岐にわたります。これらの分野では、乱数の質と制御が結果に大きく影響するため、適切な乱数ジェネレータの利用が不可欠です。AI技術の進化に伴い、乱数ジェネレータの重要性はさらに高まっていくでしょう。
統計的手法による固定化
統計的手法を用いた乱数の固定化は、AIの性能向上において重要な役割を果たします。この手法では、乱数の生成プロセスを統計的な規則に基づいて制御し、再現性を確保します。これにより、同じ条件下で何度も実験や学習を行うことが可能となり、結果の信頼性が高まります。特に、機械学習や深層学習のモデル開発において、乱数の固定化は学習プロセスの安定化に寄与します。
統計的手法の中でも、乱数テーブルや乱数ジェネレータの使用が一般的です。乱数テーブルは、事前に生成された乱数のリストを利用する方法で、特定のシード値を設定することで同じ乱数列を再現できます。一方、乱数ジェネレータは、アルゴリズムに基づいてリアルタイムで乱数を生成するため、柔軟性が高いという特徴があります。これらの手法を適切に組み合わせることで、AIの学習プロセスにおける計算速度や精度を向上させることが可能です。
さらに、統計的手法による乱数固定化は、金融リスクマネジメントやサイバーセキュリティなどの分野でも応用が期待されています。例えば、金融市場のシミュレーションにおいて、乱数を固定化することで、異なるシナリオ間での比較が容易になります。また、セキュリティ分野では、乱数を利用した暗号化技術の信頼性を高めることができます。このように、統計的手法による乱数固定化は、AI技術の進化とともに、さまざまな分野での活用が広がっています。
乱数制御の利点
乱数制御は、AIの性能向上において重要な役割を果たします。特に、機械学習や深層学習の分野では、乱数を適切に制御することで、モデルの学習プロセスが安定し、再現性が高まります。これにより、異なる環境や条件下でも同じ結果を得ることが可能となり、研究や開発の効率が大幅に向上します。
さらに、乱数を制御することで、計算速度の高速化や精度の向上が期待できます。例えば、乱数を固定化することで、同じ入力に対して常に同じ出力が得られるため、デバッグやテストが容易になります。また、乱数の生成方法を最適化することで、不要な計算を削減し、リソースの効率的な利用が可能となります。
コスト削減も乱数制御の大きな利点の一つです。乱数を適切に管理することで、計算リソースの無駄を省き、ハードウェアや電力の消費を抑えることができます。これにより、大規模なデータセットを扱う場合でも、効率的に学習を進めることが可能となります。
将来的には、金融リスクマネジメントやサイバーセキュリティなど、多くの分野で乱数制御技術が活用されることが期待されています。これらの分野では、正確な予測や高度なセキュリティ対策が求められるため、乱数を制御することで、より信頼性の高いシステムを構築することができます。
計算速度の高速化
計算速度の高速化は、AI開発において最も重要な課題の一つです。特に、大規模なデータセットを扱う際には、計算速度が遅いと学習に膨大な時間がかかってしまいます。乱数制御を適切に行うことで、計算プロセスを効率化し、無駄な計算を削減することが可能です。例えば、深層学習モデルの初期化時に乱数を固定化することで、再現性を確保しつつ、計算リソースを最適化できます。
さらに、機械学習アルゴリズムの中には、乱数に依存する部分が多く存在します。これらを制御することで、不要な計算ステップを省略し、全体の処理時間を短縮することができます。特に、並列計算や分散処理を活用する際には、乱数の固定化が計算速度の向上に大きく寄与します。これにより、AIモデルの学習時間を大幅に削減し、迅速な結果を得ることが可能となります。
また、ハードウェアアクセラレーションと組み合わせることで、乱数制御による計算速度の向上効果はさらに高まります。GPUやTPUなどの専用ハードウェアを活用し、乱数生成を最適化することで、AIモデルの学習や推論を高速化できます。これにより、リアルタイムでのデータ処理や、大規模なシミュレーションが可能となり、AIの応用範囲がさらに広がることが期待されます。
精度の向上
精度の向上は、AIモデルの性能を高める上で最も重要な要素の一つです。特に、乱数制御を適切に行うことで、モデルの学習プロセスにおける再現性が確保され、結果として精度が向上します。乱数は、初期化やデータシャッフルなど、さまざまな場面で使用されますが、その値が一定でない場合、学習結果にばらつきが生じることがあります。この問題を解決するために、乱数の固定化が有効です。固定化により、同じ条件下で何度でも同じ結果を得ることが可能となり、モデルの信頼性が高まります。
さらに、深層学習や機械学習のアルゴリズムにおいて、乱数を制御することで、過学習を防ぎ、汎化性能を向上させることも可能です。例えば、ドロップアウトやデータ拡張などの手法では、乱数が重要な役割を果たしますが、これを適切に管理することで、モデルの安定性が向上します。また、計算速度の高速化やコスト削減にもつながるため、乱数制御はAI開発において不可欠な技術と言えます。
将来的には、金融リスクマネジメントやサイバーセキュリティなど、高い精度が求められる分野で、乱数制御技術がさらに活用されることが期待されています。AIの性能向上を目指す開発者にとって、乱数制御と固定化の理解は必須であり、その効果を最大限に引き出すことが重要です。
コスト削減
AIの性能向上において、コスト削減は重要な要素の一つです。特に、大規模なデータセットを用いた機械学習や深層学習では、計算リソースの効率的な利用が求められます。乱数制御を適切に行うことで、計算プロセスを最適化し、無駄なリソース消費を抑えることが可能です。例えば、乱数を固定化することで、同じ条件下での実験を繰り返し行い、結果の再現性を高めることができます。これにより、無駄な試行錯誤を減らし、開発コストを削減することが期待されます。
さらに、乱数ジェネレータや統計的手法を用いることで、計算速度の高速化や精度の向上を図ることができます。これにより、より少ないリソースで高い性能を発揮するAIモデルを構築することが可能です。特に、金融リスクマネジメントやサイバーセキュリティなどの分野では、計算コストを抑えつつ、高い精度での予測や判断が求められるため、乱数制御技術の活用が重要視されています。
将来的には、乱数制御技術がさらに進化し、より多くの分野で活用されることが期待されています。これにより、AIの性能向上だけでなく、コスト削減やリソースの効率的な利用が実現され、より持続可能なAI開発が可能となるでしょう。
乱数制御の応用分野
乱数制御は、AIの性能向上において重要な役割を果たす技術です。特に、機械学習や深層学習の分野では、乱数を適切に制御することで、モデルの学習プロセスを安定させ、予測精度を向上させることが可能です。例えば、ニューラルネットワークの初期化やドロップアウトの適用において、乱数を固定化することで再現性を確保し、実験結果の信頼性を高めることができます。
さらに、金融リスクマネジメントやサイバーセキュリティといった分野でも、乱数制御は重要な応用が期待されています。金融分野では、リスクシミュレーションやポートフォリオ最適化において、乱数を用いたモンテカルロシミュレーションが広く利用されています。乱数を制御することで、シミュレーション結果の精度を向上させ、より信頼性の高い意思決定を支援することが可能です。
また、ゲーム開発や仮想現実(VR)の分野でも、乱数制御は重要な技術です。ゲーム内のランダムイベントやNPCの行動パターンを制御することで、プレイヤーにとってより没入感のある体験を提供することができます。これらの応用分野において、乱数制御技術はAIの性能向上に大きく貢献しています。
金融リスクマネジメント
金融リスクマネジメントにおいて、AIの性能向上は重要な課題となっています。特に、乱数制御技術の活用が、リスク評価や予測モデルの精度向上に大きく寄与しています。金融市場は常に変動しており、その中で正確なリスク評価を行うためには、AIが適切に乱数を扱うことが不可欠です。乱数を制御することで、AIはより信頼性の高い予測を提供し、リスクを最小限に抑えることが可能となります。
さらに、乱数の固定化は、再現性の確保において重要な役割を果たします。金融モデルの開発やテストにおいて、同じ条件下で結果を再現できることは、モデルの信頼性を高めるために欠かせません。乱数を固定化することで、AIは一貫した結果を提供し、リスク評価の精度を向上させることができます。これにより、金融機関はより効果的なリスク管理戦略を立てることが可能となります。
将来的には、乱数制御技術がさらに進化し、金融リスクマネジメントの分野でより広く活用されることが期待されています。AIが高度な乱数制御を実現することで、金融市場の不確実性に対応するための強力なツールとなるでしょう。
サイバーセキュリティ
サイバーセキュリティの分野において、乱数制御は極めて重要な役割を果たしています。特に、暗号化技術や認証システムにおいて、予測不可能な乱数の生成がセキュリティの強度を左右します。AIが生成する乱数は、従来の手法よりも高い精度と速度を実現し、サイバー攻撃に対する防御力を向上させることが可能です。例えば、機械学習を用いた乱数生成モデルは、過去の攻撃パターンを学習し、より安全な乱数を生成するために活用されています。
さらに、深層学習を応用した乱数制御技術は、複雑なデータパターンを解析し、高度なセキュリティ対策を実現します。これにより、フィッシング攻撃やマルウェアの検出精度が向上し、システム全体の信頼性が高まります。また、遺伝的アルゴリズムを活用することで、最適な乱数生成パラメータを自動的に調整し、セキュリティプロトコルの効率化を図ることができます。
将来的には、AIによる乱数制御技術が、金融取引や個人情報保護などの分野でも広く活用されることが期待されています。これにより、サイバーセキュリティのさらなる進化が実現し、デジタル社会の安全性が向上するでしょう。
まとめ
AIの性能向上において、乱数制御は非常に重要な要素です。乱数は、機械学習や深層学習のモデルにおいて、初期化やデータのシャッフル、ドロップアウトなど、さまざまな場面で使用されます。乱数を適切に制御することで、モデルの再現性が向上し、実験結果の信頼性が高まります。特に、異なる環境やデバイス間で同じ結果を得るためには、乱数の固定化が不可欠です。
乱数の固定化方法として、シード値の設定が一般的です。シード値を固定することで、同じ乱数列を生成することが可能になります。これにより、モデルの学習過程や評価結果を再現しやすくなります。また、乱数ジェネレータの選択も重要で、高品質な乱数を生成するジェネレータを使用することで、モデルの性能が向上することがあります。
さらに、統計的手法を用いて乱数を制御することも有効です。例えば、正規分布や一様分布に基づく乱数を生成することで、モデルの学習が安定し、過学習を防ぐことができます。これらの手法を組み合わせることで、AIの性能を最大限に引き出すことが可能です。
将来的には、金融リスクマネジメントやサイバーセキュリティなど、乱数制御技術が重要な役割を果たす分野がさらに拡大することが期待されています。AIの進化とともに、乱数制御の重要性はますます高まっていくでしょう。
よくある質問
1. 乱数制御がAIの性能向上にどのように影響するのですか?
乱数制御は、機械学習や深層学習のモデルの学習プロセスにおいて、再現性と安定性を確保するために重要です。特に、ニューラルネットワークの初期化やデータのシャッフルなど、ランダム性が関わる部分で乱数を固定化することで、同じ条件下での実験結果を再現できるようになります。これにより、モデルの性能評価やハイパーパラメータのチューニングが容易になり、AIの性能向上につながります。
2. 乱数を固定化する具体的な方法は何ですか?
乱数を固定化するためには、Pythonのrandomモジュールやnumpy、tensorflow、pytorchなどのライブラリでシード値を設定します。例えば、numpyではnumpy.random.seed(42)、tensorflowではtf.random.set_seed(42)のようにシード値を指定します。これにより、同じシード値を使うことで、毎回同じ乱数が生成され、実験の再現性が保証されます。また、複数のライブラリを使用する場合は、すべてのライブラリでシード値を統一することが重要です。
3. 乱数制御が不十分だとどのような問題が発生しますか?
乱数制御が不十分だと、実験結果の再現性が失われ、モデルの性能評価が困難になります。例えば、異なる実行ごとに異なる結果が得られると、ハイパーパラメータの最適化やモデルの比較ができなくなります。さらに、デバッグが困難になり、問題の特定や修正に時間がかかることがあります。そのため、乱数制御はAI開発において不可欠なプロセスです。
4. 乱数制御と固定化はどのような場面で特に重要ですか?
乱数制御と固定化は、研究開発やモデルの比較、ハイパーパラメータチューニングの場面で特に重要です。研究開発では、同じ条件下で実験を繰り返すことで、新しいアルゴリズムや手法の効果を正確に評価できます。また、モデルの比較では、乱数を固定化することで、異なるモデルの性能を公平に比較できます。さらに、ハイパーパラメータチューニングでは、乱数を固定化することで、最適なパラメータセットを見つけるプロセスが効率化されます。
コメントを残す
コメントを投稿するにはログインしてください。
関連ブログ記事