「ValueError: cannot set a row with mismatched columns」の解決法と予防策【Jupyter Notebook】
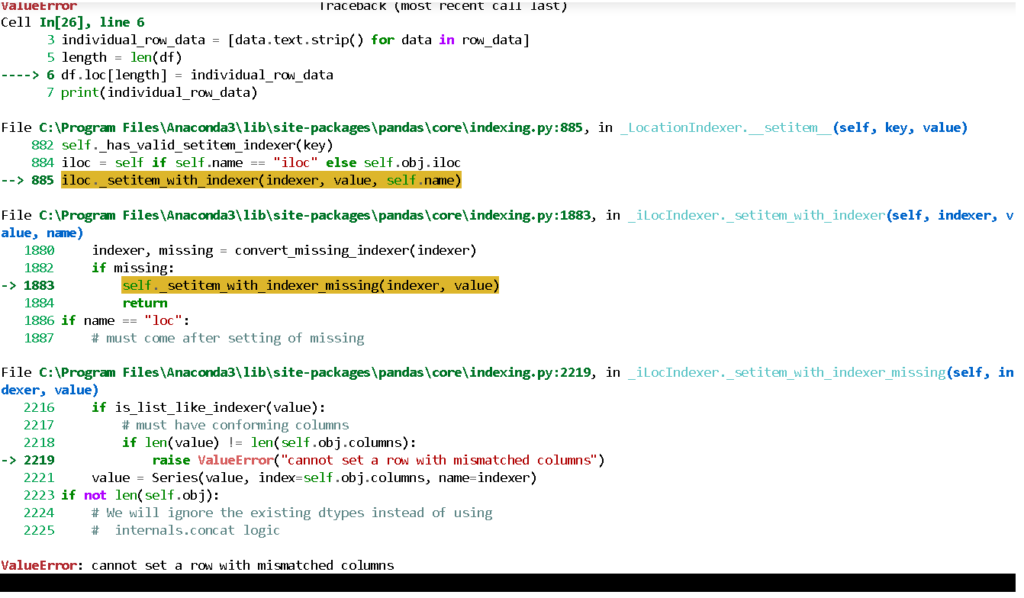
Jupyter Notebookを使用している際に、「ValueError: cannot set a row with mismatched columns」というエラーが発生することがあります。このエラーは、DataFrameの行と列の数や列名が一致していない場合に起こります。本記事では、このエラーの原因と解決法について詳しく解説します。また、エラーを未然に防ぐための予防策についても紹介します。データ分析や処理を行う際に、このようなエラーに遭遇した場合の対処法を理解しておくことは非常に重要です。エラーメッセージを正確に読み解き、データの整合性を確認することで、問題を迅速に解決できるようになります。
イントロダクション
Jupyter Notebookを使用している際に、「ValueError: cannot set a row with mismatched columns」というエラーが発生することがあります。このエラーは、DataFrameの行と列の数や列名が一致していない場合に発生します。特に、データの追加や更新を行う際に、列の数が異なっていたり、列名が正しく設定されていないと、このエラーが頻繁に発生します。
このエラーの原因を理解するためには、まずDataFrameの構造を確認することが重要です。DataFrameは行と列で構成される表形式のデータ構造であり、各行は同じ数の列を持っている必要があります。もし、新しい行を追加する際に列の数が異なっていたり、列名が一致していないと、このエラーが発生します。
エラーを解決するためには、まずDataFrameの列名と列数を確認し、追加しようとしている行がそれに一致しているかどうかをチェックします。また、自動的に列を調整する方法や、手動で列名を修正する方法もあります。さらに、エラーを予防するためには、データの整合性を定期的に確認し、DataFrameの構造が一貫していることを保証することが重要です。
この記事では、具体的な解決策と予防策について詳しく解説します。エラーメッセージを正確に読み解き、データの内容や形状を再確認することで、問題を迅速に解決できるようになります。
エラーの原因
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーが発生する主な原因は、DataFrameの行と列の整合性が取れていないことです。具体的には、新しい行を追加しようとした際に、その行の列数が既存のDataFrameの列数と一致していない場合や、列名が異なっている場合にこのエラーが発生します。例えば、列数が異なるデータを無理やり結合しようとすると、PythonのPandasライブラリはこのエラーを出力します。
また、列名が異なる場合も同様の問題が発生します。DataFrameの列名は、行を追加する際に重要な役割を果たします。列名が一致していないと、どの列にどのデータを割り当てるべきかがわからず、エラーが発生します。このような状況は、異なるソースからデータを結合する際によく見られます。
さらに、データの形状が予期せず変化している場合にもこのエラーが発生することがあります。例えば、データの前処理中に意図せず列が削除されたり、追加されたりすると、行と列の整合性が崩れてしまいます。そのため、データ操作を行う際には、常にデータの形状を確認することが重要です。
エラーの解決方法
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーが発生した場合、まずはDataFrameの列数と列名が一致しているか確認することが重要です。このエラーは、行を追加または更新しようとした際に、指定したデータの列数や列名が既存のDataFrameと一致しない場合に発生します。例えば、異なる列数を持つデータを追加しようとすると、このエラーが発生します。
解決策の一つとして、手動で列名や列数を調整する方法があります。DataFrameの列名を確認し、追加するデータの列名と一致させることでエラーを回避できます。また、pd.concat()やDataFrame.append()を使用する際に、ignore_index=Trueやsort=Falseなどのオプションを適切に設定することで、列の整合性を保つことができます。
さらに、自動的に列を調整する方法もあります。例えば、DataFrame.reindex()を使用して、既存のDataFrameの列に合わせて新しいデータの列を再配置することが可能です。これにより、列の順序や数が異なる場合でも、エラーを防ぐことができます。
最後に、データの整合性を定期的に確認する習慣をつけることが重要です。特に、複数のデータソースからデータを結合する場合や、異なる形式のデータを扱う場合には、事前に列名や列数を確認することで、このエラーを未然に防ぐことができます。
列名の調整
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーが発生した場合、列名の不一致が原因であることが多いです。このエラーは、DataFrameに新しい行を追加しようとした際に、列名が既存のDataFrameと一致しない場合に発生します。例えば、列名が異なる順序で並んでいたり、一部の列名が欠落している場合などが考えられます。
この問題を解決するためには、まず列名を確認し、既存のDataFrameと新しい行の列名が完全に一致しているかをチェックします。列名が異なる場合は、df.columnsを使用して列名を手動で調整するか、pd.concat()やdf.reindex()などの関数を使って自動的に列名を揃えることができます。特に、pd.concat()のignore_indexパラメータやjoinパラメータを適切に設定することで、列名の整合性を保つことが可能です。
また、列名の調整を行う際には、データの内容が変わらないように注意が必要です。列名を変更すると、その列に紐づくデータも影響を受けるため、慎重に作業を進めることが重要です。特に、大規模なデータセットを扱う場合、列名の調整がデータの整合性に与える影響は大きいため、事前にバックアップを取るなどの予防策を講じることをお勧めします。
列数の調整
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーが発生した場合、その原因の一つとして列数の不一致が挙げられます。このエラーは、DataFrameに行を追加または更新しようとした際に、指定した行の列数が既存のDataFrameの列数と一致しない場合に発生します。例えば、5列のDataFrameに対して4列しか持たない行を追加しようとすると、このエラーが発生します。
この問題を解決するためには、まず列数を確認することが重要です。DataFrameの列数はdf.shape[1]で確認できます。追加または更新しようとしている行の列数がこれと一致しているかどうかを確認しましょう。もし列数が一致していない場合、不足している列を追加するか、余分な列を削除することで調整できます。例えば、NaN値を含む列を追加して列数を合わせる方法があります。
また、列数を自動的に調整する方法もあります。pd.concat()関数を使用して、複数のDataFrameを結合する際にignore_index=Trueを指定することで、列数が自動的に調整される場合があります。ただし、この方法を使用する際は、列名が一致しているかどうかも確認する必要があります。列名が異なる場合、意図しないデータの混在が発生する可能性があるため、注意が必要です。
予防策として、DataFrameに新しい行を追加する前に、必ず列数と列名を確認する習慣をつけることが重要です。これにより、エラーの発生を未然に防ぐことができます。また、データの整合性を保つために、定期的にDataFrameの形状や内容を確認することをお勧めします。
予防策
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーを防ぐためには、データの整合性を常に確認することが重要です。まず、DataFrameを作成または操作する際に、列名と列数が一致しているかを確認しましょう。特に、異なるソースからデータを結合する場合や、新しい行を追加する際には、列の順序や名前が正しく設定されているかを入念にチェックする必要があります。
さらに、データの前処理段階で、列の数や名前が一貫しているかを確認するスクリプトを用意することも有効です。例えば、DataFrameの形状を確認するためにdf.shapeを使用したり、列名を確認するためにdf.columnsを活用したりすることで、予期せぬエラーを未然に防ぐことができます。また、データの整合性チェックを自動化するための関数を作成し、定期的に実行することで、エラーの発生リスクを大幅に低減できます。
最後に、データの変更履歴を記録しておくことも重要です。特に、複数の人が同じデータを操作する場合、変更内容を追跡できるようにすることで、エラーの原因を特定しやすくなります。これにより、「ValueError: cannot set a row with mismatched columns」のようなエラーが発生した場合でも、迅速に対処することが可能になります。
データの整合性確認
データの整合性確認は、Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーを解決するための最初のステップです。このエラーは、DataFrameの行と列の数や列名が一致しない場合に発生します。まず、DataFrameの形状や列名を確認し、データが正しく読み込まれているかどうかをチェックします。特に、CSVファイルやExcelファイルからデータを読み込む際には、列名やデータ型が正しく設定されているかを確認することが重要です。
次に、DataFrameの行と列の整合性を確認するために、df.shapeやdf.columnsを使用して、行数や列数、列名を確認します。これにより、DataFrameの構造が期待通りであるかどうかを確認できます。また、df.info()を使用して、各列のデータ型や欠損値の有無を確認することも有効です。これらの確認作業を行うことで、データの整合性を保ち、エラーの発生を未然に防ぐことができます。
さらに、データの整合性確認は、定期的に行うことが推奨されます。特に、データの更新や変更が頻繁に行われる場合には、DataFrameの構造が変わっていないかを定期的にチェックすることが重要です。これにより、エラーの発生を最小限に抑え、スムーズなデータ処理を実現できます。
エラーメッセージの読み解き方
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーメッセージが表示された場合、まずはそのメッセージが何を意味しているのかを正確に理解することが重要です。このエラーは、DataFrameの行を設定しようとした際に、列の数や列名が一致していないために発生します。具体的には、新しい行を追加する際に、既存のDataFrameの列数と異なる数のデータを渡してしまったり、列名が異なる場合にこのエラーが発生します。
エラーメッセージを読み解く際には、まずDataFrameの構造を確認することが第一歩です。DataFrameの列名や列数を確認し、新しい行を追加する際にそれらが一致しているかどうかをチェックします。また、エラーメッセージが発生したコードの部分を特定し、どの行で問題が起きているのかを把握することも重要です。これにより、問題の原因を迅速に特定し、適切な修正を行うことができます。
さらに、エラーメッセージが表示された際には、データの内容や形状を再確認することも有効です。特に、外部からデータを読み込んだり、複数のDataFrameを結合したりする場合には、列名や列数が一致しているかどうかを事前に確認することで、このエラーを未然に防ぐことができます。
まとめ
Jupyter Notebookで「ValueError: cannot set a row with mismatched columns」というエラーが発生した場合、その原因は主にDataFrameの行と列の整合性が取れていないことにあります。このエラーは、行を追加または更新する際に、列の数や列名が一致しない場合に発生します。例えば、異なる列数を持つ行を追加しようとしたり、列名が異なるデータを結合しようとしたりすると、このエラーが発生します。
このエラーを解決するためには、まずDataFrameの構造を確認することが重要です。具体的には、列名や列数が一致しているかどうかをチェックし、必要に応じて手動で調整します。また、自動的に列を調整する関数やメソッドを利用することも有効です。例えば、pd.concat()やdf.reindex()を使用することで、列の整合性を保つことができます。
エラーを予防するためには、データの整合性を定期的に確認する習慣をつけることが大切です。特に、異なるソースからデータを結合する場合や、新しいデータを追加する際には、列名や列数が一致しているかどうかを事前に確認しましょう。また、エラーメッセージを正確に読み解くことで、問題の原因を迅速に特定し、適切な対策を講じることができます。これにより、データ処理の効率を向上させ、エラーを未然に防ぐことが可能になります。
よくある質問
「ValueError: cannot set a row with mismatched columns」とはどのようなエラーですか?
このエラーは、Jupyter Notebook で Pandas のデータフレームを操作している際に、行を設定しようとした際に列の数が一致しない場合に発生します。具体的には、DataFrame.loc や DataFrame.iloc を使用して行を追加または更新しようとした際に、指定したデータの列数が既存のデータフレームの列数と一致しないと、このエラーが発生します。列の数が異なることが主な原因であり、データの整合性を保つために重要なエラーです。
このエラーを解決するにはどうすればよいですか?
このエラーを解決するためには、列の数を一致させることが重要です。まず、DataFrame.shape を使用して、データフレームの列数を確認します。次に、追加または更新しようとしているデータの列数が同じであることを確認します。もし列数が異なる場合は、DataFrame.reindex や DataFrame.drop を使用して列を調整するか、NaN で不足している列を埋めることが有効です。また、DataFrame.append や DataFrame.concat を使用して新しいデータを追加する際にも、列の整合性を確認することが重要です。
このエラーを予防するためのベストプラクティスは何ですか?
このエラーを予防するためには、データの整合性を常に確認することが重要です。特に、新しいデータを追加する際には、列の数と名前が一致しているかを事前に確認します。また、DataFrame の操作を行う前に、assert 文を使用して列数が一致しているかをチェックする方法も有効です。さらに、try-except ブロックを使用してエラーをキャッチし、適切なエラーメッセージを表示することで、デバッグを容易にすることができます。定期的にデータフレームの構造を確認する習慣をつけることも、予防策として有効です。
このエラーが発生した場合、どのようにデバッグすればよいですか?
このエラーが発生した場合、まずは print や DataFrame.info() を使用して、データフレームの構造を確認します。特に、列数と列名が一致しているかを重点的にチェックします。次に、エラーが発生している行のコードを確認し、どの部分で列数が不一致になっているかを特定します。必要に応じて、len() 関数を使用してデータの列数を確認し、問題のある部分を修正します。また、Jupyter Notebook の セルを分割して、段階的にデータを確認することもデバッグの効率を上げるために有効です。
コメントを残す
コメントを投稿するにはログインしてください。
関連ブログ記事